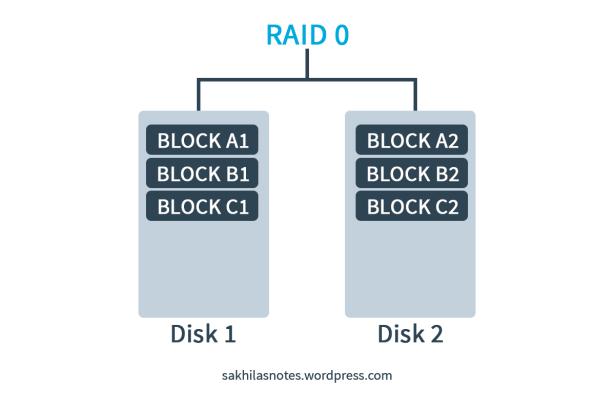
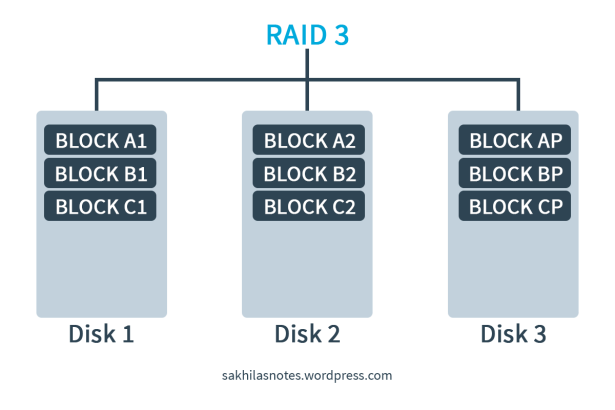
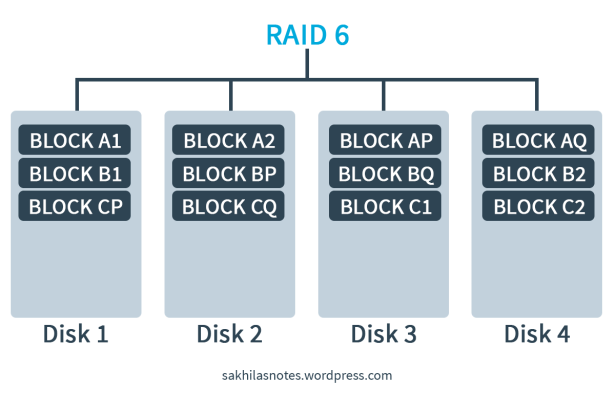
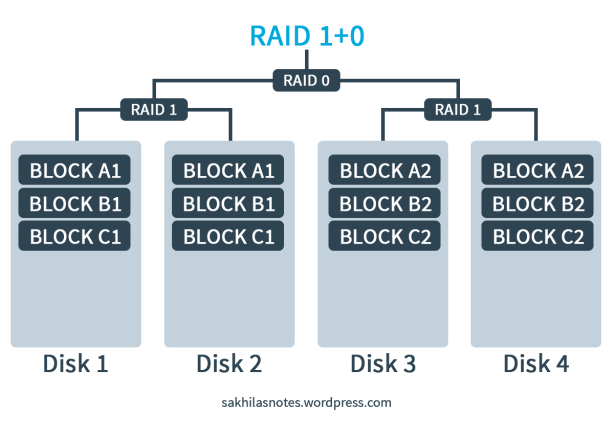
I’ve written about the RAID system and its techniques and levels in a previous entry. Please Click Here! In this article I am discussing a RAID 3 implementation using the tool called MD (Multiple Disks) Driver; AKA the Software RAID.
Software RAID vs. Hardware RAID
There are two possible approaches in implementing RAID: Hardware RAID and Software RAID. Software RAID (S/W RAID) implements the various RAID levels in block devices. It is the cheapest solution. Because here expensive hardware devices such as disk controller cards or hot-swap chassis are not required. S/W RAID also works with cheaper IDE disks as well as SCSI disks. With today’s fast CPUs, S/W RAID systems can perform better than Hardware RAID.
But anyways, S/W RAID comsumes the CPU cycles from the Processor of the host. In larger scale scenarios this can lead to many problems. The Hardware RAID (H/W RAID) manages the RAID subsystem independently from the host with the use of dedicated hardware devices to handle the operations. In this, host sees only a single disk per RAID array.
Back to work! In this S/W RAID implementation, I use 3 disks for the data and a additional one disk as a Hot Spare. A Hot Spare is a backup component that can be placed into service immediately when a primary component fails.

The MD driver provides virtual devices that are created from one or more independent underlying devices. In other words; after implementing the this RAID 3 system, it will be shown as a single disk to the user. But there are 4 underlying disk drives which actually hold the data.
For this implementations, firstly we have to install the tool MDADM (MD Administrator) to the system. We can do this using a simple YUM command.
# yum install mdadm
Then we have to select a set of disks/partitions for the RAID 3 system. For this we need 3 volumes as primary devices and another as the hot spare. The importance is, if the requirement is a RAID disk with the capacity of 4GB; the selected for volumes we selected should be equals or greater than 4GB. Let’s say we use the followings for the task.
/dev/sdb1 4GB /dev/sdb2 4GB /dev/sdc 4GB /dev/sdd 4GB
Then we can create the RAID 3 Disk using the mdadm command. Here; we can either define the Hot Spare in the creation itself or create the RAID Disk without a hot spare.
# mdadm --create /dev/mda --level=3 --raid-devices=3 /dev/sdb1 /dev/sdb2 /dev/sdc or # mdadm --create /dev/mda --level=3 --raid-devices=3 /dev/sdb1 /dev/sdb2 /dev/sdc --spare-devices=1 /dev/sdd
The options in the command stand for the followings;
–create defines the creation the RAID disk (mda)
–level defines the RAID level
–raid-devices defines the disks/partitions for primary devices
–spare-devices defines the disks/partitions for spare devices
Then as we do with normal disks/partitions, we should install a file system to the RAID disk and mount it to a mount point.
# mkfs.ext4 /dev/mda # mkdir /raidDisk # mount /dev/mda /raidDisk
Now the user can access the RAID Disk mda via the /raidDisk mount point, treating it as a normaly mounted disk. User has no idea about the underlying disk arrengement. You can display the details about the RAID Disk arrengement using the following command.
# mdadm --detail /dev/mda
Data Recoverying Process in a Disk Failure
We can test the functionality of the RAID system by failing a primary device. In this case there are two scenarios. First is where you have a Hot Spare. The other scenario is when you have not configured a Hot Spare. First let’s see how to fail a drive.
# mdadm --manage /dev/mda --fail /dev/sdb1
With the above command now the drive sdb1 is failed. If there is a Hot Spare drive, now automaticall the lost data will be recovered in to it, the drive sdd.
If a Hot Spare is not assigned; the administrator should quickly remove the failed drive from the RAID system. It can be done using the following command;
# mdadm --manage /dev/md0 -r /dev/sdb1
Then the administrator should manually add a Spare Drive which is equal or greater than 4GB. Then quickly RAID system will start the recovering process. We can add a Spare drive (sde) to the system with the following command;
# mdadm --manage /dev/md0 -a /dev/sde
Either way is possible. To monitor the recoverying process we can display the MD Statistics using the following command.
# watch -n1 cat /proc/mdstat
What is a Hot Spare Drive and a Spare Drive?
Hot Spare drive is a pre defined disk drives with the relevant requirements (such as capacity) and it works automatically in a drive failure. And a Spare drive is another disk drive with the relevant requirements and it is not pre defined. In case of drive failure; administrators can manually add the drive to the RAID system.
Remove a RAID Disk.
Under this sub topic lets discuss how to remove a RAID disk from the system and free the underlying disks/partitions. For this first we can check for the existing RAIDs using the following command.
# cat /proc/mdstat
The we need to unmount the RAID device.
# umount /dev/mda
Then we need to stop and remove the RAID array from the system. After executing this; the RAID controller will release the processes relevant to the particular RAID disk.
# mdadm --stop /dev/md0 mdadm --remove /dev/md0
To check for RAID dedicated underlying disks/partitions we can use the following command.
# lsblk -o NAME,SIZE,FSTYPE,TYPE,MOUNTPOINT
To release those disks/partitions we can follow the following commands;
# mdadm --zero-superblock /dev/sdb1 # mdadm --zero-superblock /dev/sdb2 # mdadm --zero-superblock /dev/sdc # mdadm --zero-superblock /dev/sdd
By following this note; you will be able to configure a software RAID Disk successfully. With the practical approach only you can understand somethings in deap.
Good Luck & Have Fun!